Technical aspects related to automatic calculations with ABINIT¶
M. Giantomassi and the AbiPy group¶
9th international ABINIT developer workshop
20-22nd May 2019 - Louvain-la-Neuve, Belgium

Overview:¶
- Approach used to connect AbiPy with Abinit
- Advantages and drawbacks of Yaml and netcdf
- Technical problems related to automatic calculations and possible solutions
What do we need to automate calculations?¶
- Tools to parse and analyze output results
- Programatic interface to generate input files
- High-level logic for:
- Managing complicated workflows
- Exposing task parallelism (independent steps can be executed in parallel)
- Handling runtime errors and restarting calculations
- Saving final results in machine-readable format (e.g. databases)
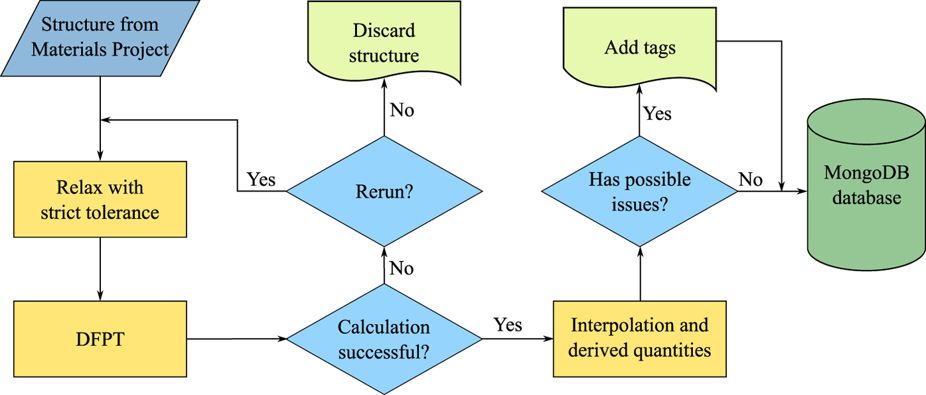
Workflow infrastructure¶
Two different approaches:
AbiPy workflows (flowtk):¶
- Lightweight implementation (pymatgen + AbiPy)
- No database required. Object persistence provided by pickle
- Ideal tool for prototyping, testing, debugging.
AbiFlows workflows:¶
- Based on fireworks
- Requires MongoDb database
- Designed and optimized for high-throughput applications (Guido's talk)
Both approaches share the same codebase (AbinitInput, factory functions, AbiPy objects, TaskManager...).
Number and type of calculations are important ➝ choose according to your needs.
Main features of workflows¶
- Factory functions for typical calculations (DFPT, GW, BSE, EPH, ...)
- Support for different resource managers (Slurm, PBS, Torque, SGE, LoadLever, shell)
- autoparal: the number of MPI processes is optimized at runtime
- Iterative algorithms are automatically restarted by the framework
- Error handlers for common runtime failures
AbinitInput object¶
Programmatic interface to generate input files:
- Dict-like object storing ABINIT variables
- Methods to set multiple variables (e.g. k-path from structure)
- Factory functions to generate input files with minimal effort
Can invoke ABINIT to get important parameters such as:
- list of k-points in the IBZ
- list of irreducible perturbations for DFPT
- list of possible configurations for MPI jobs (npkpt, npfft, npband …)
To build an input, we need a structure and a list of pseudos:¶
inp = abilab.AbinitInput(structure="si.cif", pseudos="si.psp8")
Low-level API (should look familiar to Abinit users):¶
inp["ecut"] = 8
"ecut" in inp
Use set_vars to set the value of several variables with a single call:¶
inp.set_vars(kptopt=1, ngkpt=[2, 2, 2],
shiftk=[0.0, 0.0, 0.0, 0.5, 0.5, 0.5] # 2 shifts in one list
);
althought it's much easier to use:¶
inp.set_autokmesh(nksmall=2)
Interfacing Abinit with Python via AbinitInput¶
Once we have an AbinitInput, it is possible to execute Abinit to:
- get useful data from the Fortran code (e.g. IBZ, space group…)
- validate the input file before running the calculation
Methods invoking Abinit start with the abi prefix followed by a verb:
- inp.abiget_irred_phperts(...)
- inp.abivalidate()
Important:¶
To call Abinit from AbiPy, one has to prepare a configuration file (manager.yml) providing all the information required to execute/submit Abinit jobs:
$PATH,$LD_LIBRARY_PATH- modules (if any)
For futher info consult the documentation
Example of manager.yml for laptops (shell adapter)¶
qadapters:
# List of qadapters objects
- priority: 1
queue:
qtype: shell
qname: localhost
job:
mpi_runner: mpirun
pre_run:
# abinit exec must be in $PATH
- export PATH=$HOME/git_repos/abinit/_build/src/98_main:$PATH
limits:
timelimit: 30:00
max_cores: 2
hardware:
num_nodes: 1
sockets_per_node: 1
cores_per_socket: 2
mem_per_node: 4Gb
Examples of configuration files for clusters available here
Use abirun.py doc_manager to get documentation inside the shell
An example for a Slurm-based cluster¶
hardware: &hardware
num_nodes: 80
sockets_per_node: 2
cores_per_socket: 12
mem_per_node: 95Gb
job: &job
mpi_runner: mpirun
modules: # Load modules used to compile Abinit
- intel/2017b
- netCDF-Fortran/4.4.4-intel-2017b
- abinit_8.11
pre_run: "ulimit -s unlimited"
# Slurm options.
qadapters:
- priority: 1
queue:
qtype: slurm
qname: large
limits:
timelimit: 0-0:30:00
min_cores: 1
max_cores: 48
min_mem_per_proc: 1000
max_mem_per_proc: 2000
max_num_launches: 10
hardware: *hardware
job: *job
To get the list of k-points in the IBZ as computed by Abinit:¶
ibz = inp.abiget_ibz()
print("Number of k-points:", len(ibz.points))
print("Weights normalized to:", ibz.weights.sum())
n = min(5, len(ibz.points))
for i, (k, w) in enumerate(zip(ibz.points[:n], ibz.weights[:n])):
print(i, "kpt:", k, "weight:", w)
if n != len(ibz.points): print("...")
- Being able to call ABINIT from python is crucial for implementing automatic calculations, especially when symmetries and $\bf{k}$-points are involved
- The calculation is done in Fortran so ABINIT is always right even when it's wrong!
To get the list of possible parallel configurations for this input up to max_ncpus:¶
inp["paral_kgb"] = 1
pconfs = inp.abiget_autoparal_pconfs(max_ncpus=5)
print("Best efficiency:\n", pconfs.sort_by_efficiency()[0])
#print("Best speedup:\n", pconfs.sort_by_speedup()[0])
- python will select the "optimal" configuration according to some criterion and additional constraints specified by the user e.g. exclusive node allocation
To get the list of irreducible phonon perturbations for a given q-point:¶
inp.abiget_irred_phperts(qpt=(0.25, 0, 0))
To get the irreducible perturbations for strain calculations:¶
inp.abiget_irred_strainperts()
- DFPT perturbations are independent hence jobs can be executed in parallel
- Handling errors in calculations with datasets is not trivial ➔ Divide and conquer approach
- These methods represent the building block to generate workflows at runtime.

- ABINIT and AbiPy communicate through Yaml docs in log and netcdf files
- AbiPy uses this protocol to:
- generate input files
- handle errors
- implement high-level logic
- Config options required to run/submit calculations are specified in manager.yml
- Programmatic interface to set number of MPI procs and job parameters
Why two formats?¶
Each format has pros and cons:
YAML
- Mainly used for small documents:
- error messages in log file
- autoparal section and list of DFPT perturbations
- Easy to write with plain Fortran write (provided doc is flat)
- Not designed for big-data and performance
- Yaml should be used when both human- and machine-readability are wanted (cfr. Theo's talk)
- Mainly used for small documents:
Netcdf4
- Portable binary format. Can handle big-data and metadata efficiently with MPI-IO
- ETSF-IO specifications for crystalline structures, wavefunctions, densities…
- Still, ETSF-IO specs are not enough as we need hdr_t to restart. Besides many physical properties are not covered by the standard
- A machine-readable format is also human-readable. Just put some python code around it!
Error messages in Yaml¶
Fortran API¶
MSG_ERROR("Fatal error!")
MSG_BUG("This is a bug!")
ABI_CHECK(natom > 0, sjoin("Input natom must be > 0 but was:", itoa(natom))
- Macros to call the error handler and MPI_ABORT to terminates all processes
- Never ever use plain Fortran stop in MPI codes
Yaml doc printed to log file and ABI_ABORT_FILE¶
--- !ERROR
src_file: m_invars1.F90
src_line: 314
mpi_rank: 0
message: |
Input natom must be > 0, but was -42
...
- src_file and str_line added by CPP (see abi_common.h)
- message: String meant for users. It might be used by AbiPy for quick fixes although we usually prefer a more robust approach...
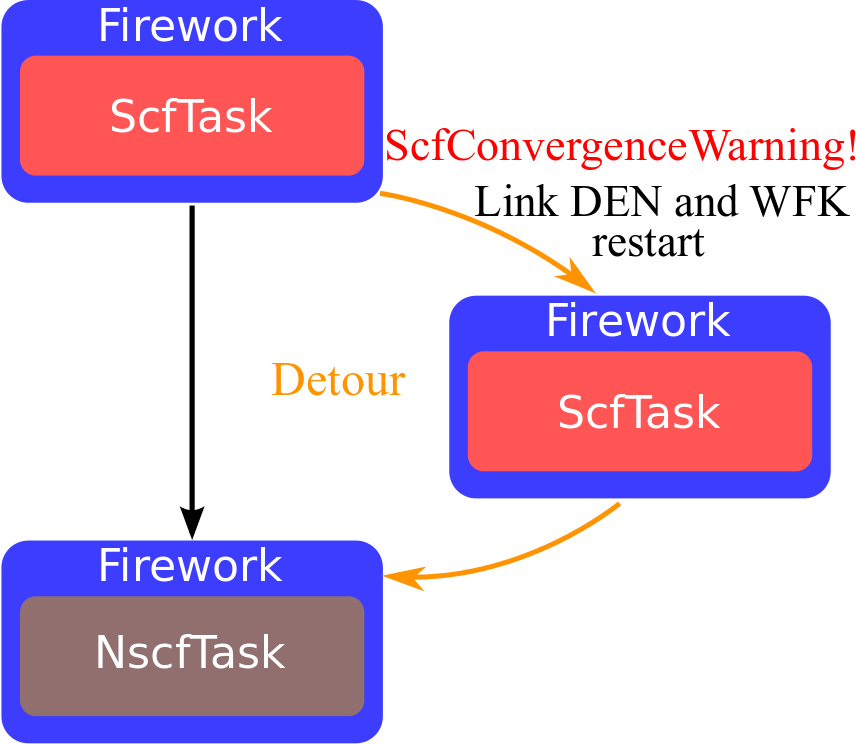
Specialized error classes¶
- Runtime errors appearing with a certain frequency are associated to specialized error classes:
MSG_ERROR_CLASS(dilatmx_errmsg, "DilatmxError")
These classes bring metadata and/or imply some action at the Fortran level
The presence of the Yaml error in the log file triggers specialized python logic:
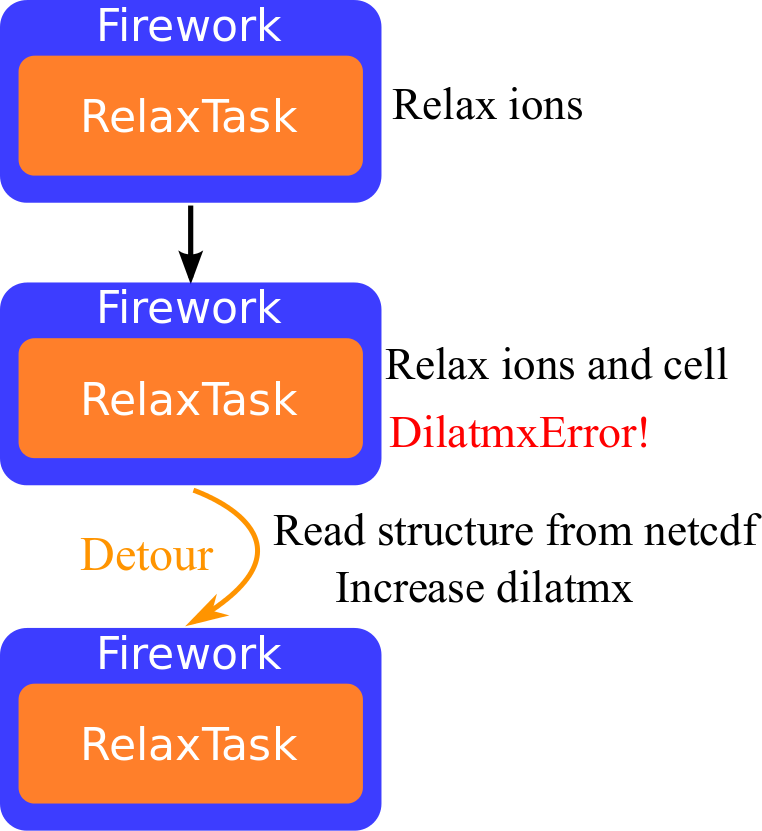
- As usual, error handling requires some discipline 🧘...
Fortran handler based on YAML + netcdf¶
call chkdilatmx(dt_chkdilatmx, dilatmx, rprimd, rprimd_orig, dilatmx_errmsg)
if (len_trim(dilatmx_errmsg) /= 0) then
! Write last structure before aborting so that we can restart from it.
if (my_rank == master) then
NCF_CHECK(crystal%ncwrite_path("out_DILATMX_STRUCT.nc")))
end if
call xmpi_barrier(comm_cell)
write(dilatmx_errmsg, '(a,i0,3a)') &
'Dilatmx has been exceeded too many times (', nerr_dilatmx, ')',ch10, &
'Restart calculation from larger lattice vectors and/or a larger dilatmx'
MSG_ERROR_CLASS(dilatmx_errmsg, "DilatmxError")
end if
- If
!DilatmxErrorin log file, AbiPy expects a ncfile with the last structure - Note MPI_BARRIER to guarantee that the ncfile is written before MPI_ABORT
How do we understand that the job completed successfully?¶
--- !FinalSummary
program: abinit
version: 8.11.6
start_datetime: Sat Mar 30 23:01:14 2019
end_datetime: Sat Mar 30 23:04:04 2019
overall_cpu_time: 168.8
overall_wall_time: 169.7
exit_requested_by_user: no
timelimit: 0
pseudos:
Li : 9517c0b7d24d4898578b8627ce68311d
F : 14cf65a61ba7320a86892d2f062b1f44
usepaw: 0
mpi_procs: 1
omp_threads: 1
num_warnings: 2
num_comments: 73
...
- Understanding whether the job is still running or stuck is more difficult since there's no "official protocol" implemented by resource managers
- AbiPy analyzes stderr files and uses heuristic rules to detect this kind of problem
Netcdf files in Abinit¶
Philosophy¶
- A ncfile is a container of "objects"
- Each object implements the ncwrite method to dump its status
- Client code uses these methods to implement composition
- A GSR.nc file, for instance, has a crystal, an header, ebands and results_gs
Fortran code for GSR.nc¶
ncerr = nctk_open_create(ncid, "si_scf_GSR.nc", xmpi_comm_self)
! Write hdr, crystal and band structure
ncerr = hdr%ncwrite(ncid, fform_den, nc_define=.True.)
ncerr = crystal%ncwrite(ncid)
ncerr = ebands%ncwrite(ncid)
! Add energy, forces, stresses
ncerr = results_gs%ncwrite(ncid, dtset%ecut, dtset%pawecutdg)
ncerr = nf90_close(ncid)
The same pattern can be used for other files:¶
NCF_CHECK(nctk_open_create(ncid, "out_PHDOS.nc", xmpi_comm_self))
! PHDOS.nc has a crystalline structure + DOS values
NCF_CHECK(cryst%ncwrite(ncid))
NCF_CHECK(phdos%ncwrite(ncid)
Advantages of ncwrite API:¶
- Code reuse. Need to implement extra logic only for extra data
- Standardized format for hdr, crystal, ebands ...
- Post-processing tools need metadata (e.g. crystal) to interpret the data
- Less boiler-plate code to implement parsers and post-processing tools
Abipy implementation based on mixins:¶
class GsrFile(AbinitNcFile, Has_Header, Has_Structure, Has_ElectronBands):
"""This file contains ground-state results"""
class FatBandsFile(AbinitNcFile, Has_Header, Has_Structure, Has_ElectronBands):
"""This file contains LM-projected bands"""
Easy-to-use API that plays well with the dynamic nature of the python language¶
for path in ("out_GSR.nc", "out_FATBANDS.nc", "out_WFK.nc", "out_SIGEPH.nc"):
abifile = abilab.abiopen(path)
abifile.ebands.plot()

- Restart capabilities and IO
- Extending TesSuite with AbiPy
- TestSuite is too gentle but clusters are dark and full of errors 🐉🐉🐉
- Using AbiPy to benchmark ABINIT
Restart capabilities and IO¶
Clean exit with --timeline and smart-io mode (prtwf -1)¶
$ cat job.sh
#SBATCH --time=12:00:00
abinit --timelimit 12:00:00 < run.file > run.log 2> run.err
- Available for iterative algorithms (Relax, Scf)
- Compute wall-time required by one iteration, save intermediate results if timelimit is approaching so that restart is possible
- prtwf -1: Print WFK only if not converged to reduce IO-pressure and avoid disk-quota
- Abipy will restart the job from the previous results
Restart from netcdf file¶
- EPH approach: Save results to SIGEPH with table done(ikpt, spin)
Unfortunately:¶
- Not all the drivers support restart e.g. GW or BSE
- Output of certain files may use smart-io mode by default e.g. first-order WFK
- The number of files per user is limited. Should make list of files that may be removed e.g. _OUT.nc
Extending TestSuite with AbiPy¶
- More that 1200 tests in TestSuite still the infrastructure is not bulletproof
- We assume the reference results are always correct but
- mistakes may happen when updating refs
- in comes cases, inconsistencies can be spotted by analyzing the raw data
Based on a true story:¶
- A bug in the calculation of the atom-projected phonon DOS entered trunk/develop
- All the refs were updated so buildbot was happy!
- I had a look at the diffs but it was like finding needle in the haystack
- Fortunately, AbiPy detected the problem because there was a test based on the post-processing of the numerical results...
# Test whether projected DOSes computed by anaddb integrate to 3*natom.
ddb = abilab.abiopen("out_DDB")
for dos_method in ("tetra", "gaussian"):
# Get phonon bands and dos with anaddb.
phbst_nc, phdos_nc = ddb.anaget_phbst_and_phdos_files(dos_method=dos_method)
phbands, phdos = phbst_nc.phbands, phdos_nc.phdos
# Total PHDOS should integrate to 3 * natom
assert_almost_equal(phdos.integral_value, len(phbands.structure) * 3)
# Summing projected DOSes over types should give the total DOS.
pj_sum = sum(pjdos.integral_value for pjdos in phdos_file.pjdos_symbol.values())
assert_almost_equal(phdos.integral_value, pj_sum)
# Summing proj-DOSes over types and directions should give the total DOS.
values = phdos_file.reader.read_value("pjdos_rc_type").sum(axis=(0, 1))
tot_dos = abilab.Function1D(phdos.mesh, values)
assert_almost_equal(phdos.integral_value, tot_dos.integral_value)
Want to run the test in parallel with MPI? Just add:¶
for mpi_procs in range(1, 10**23):
ddb.anaget_phbst_and_phdos_files(dos_method=dos_method, mpi_procs=mpi_procs)
TestSuite is too gentle but clusters are dark and full of errors 🐉🐉🐉¶
Stress testing involves testing beyond normal operational capacity, often to a breaking point in order to:
- determine breaking points or safe usage limits
determine how exactly a system fails
(wikipedia)
Questions:¶
- How many tests do we perform before saying that one algo is clearly superior to another one?
- Do we have a suite of input systems designed to reveal weaknesses in algorithms?
- Is it possible to handle some of these errors at the Fortran level?
Stress testing is not easy because one needs logic to cope with errors¶
- AbiPy uses integration tests to check ErrorHandlers in which the code is supposed to fail several times before giving the right answer.
- I'm not claiming that stress testing with AbiPy is gonna be easy, but it's clear that TestSuite was not designed with this goal in mind.
Using AbiPy to benchmark ABINIT¶
- The programmatic API allows one to write benchmarks in a few lines of code
- Want to analyze the strong scaling efficiency of the GS solver with different configurations of MPI/OMP and input variables?
# Titanium with 256 atoms and k-point sampling.
# GS calculations with paral_kgb == 1 and different values of wfoptalg.
# List of MPI distribution.
pconfs = [
dict(npkpt=2, npband=8 , npfft=8 ), # 128
dict(npkpt=2, npband=8 , npfft=16), # 256
dict(npkpt=2, npband=16, npfft=16), # 512
]
omp_list = [1, 2, 4] # List of OpenMP threads
flow = BenchmarkFlow()
template = generate_input()
for wfoptalg in [1, 10, 14]:
work = flowtk.Work()
for d, omp_threads in product(pconfs, omp_list):
mpi_procs = reduce(operator.mul, d.values(), 1)
manager = manager.new_with_fixed_mpi_omp(mpi_procs, omp_threads)
inp = template.new_with_vars(d, wfoptalg=wfoptalg)
work.register_scf_task(inp, manager=manager)
flow.register_work(work)
flow.allocate()